
I came across a presentation on Youtube by Bjarne Soustrup in which he claimed that linked lists are usually the wrong data structure. As an example he used the following
- You have a random stream of N integers
- You have to insert each one in turn in the right place in a list to make the numbers in the list be in ascending order.
- You then remove them from the list in random order.
The question is, at what value of N does it become faster to use a linked list rather than a vector (array). Intriguingly, Soustrup wrote the program and benchmarked the results but his graph disappeared from his presentation. However, it’s pretty easy to do it for yourself and recreate the graph. Indeed, if you read the comments, several people have done so. So, I thought, let’s have a go in Swift.
The answer is not what some people would expect. You’re supposed to think that inserting into a list is a constant time operation but inserting into an array is O(n) because you have to shift (on average) n/2 elements up one to make space for the insertee. Unfortunately, you’d be wrong because the initial search is O(n). O(n) + 1 is O(n) and so is O(n) + O(n).
The big O time complexity for the whole algorithm is O(n2) for both the list and array approach, but linked lists are very cache unfriendly. Firstly, they are bigger due to the overhead for pointers, secondly they are all over the place making it hard to avoid cache misses.
In order to make things a little bit easier, I designed a framework to do the menial stuff of timing the operation. After fiddling around with protocols for a bit, trying to get an Array to conform to it, I decided to encapsulate my data structures in a class hierarchy. This adds a level of unnecessary indirection to the array operations but I wanted to get the basic idea working before investigating the potential problems with my model.
First simple run with only eight data points is shown in the graph below.
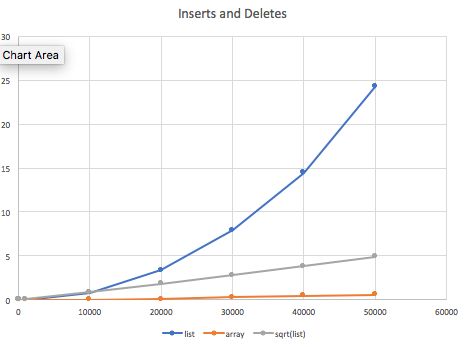
The blue line is the linked list run. The grey straight line is the square root of the linked list run (proving that the algorithm is O(n2)) and the orange line is the array run.
The URL for the code that generated the above is:
https://bitbucket.org/jeremy-pereira/datastructurebm/commits/tag/first_run
Some observations:
- The orange line for the array increases but not as a quadratic function. Ignoring the lowest values, it starts out at about 25 times faster than the linked list, increases its advantage to over 40 times faster by 20,000 elements and then drops back to around 25 again and then increases again. I suspect that the effect is due to the way the standard library allocates space to arrays.
- It turned out to be quite tricky to write the linked list implementation. It took me an hour to debug my implementation which had three basic bugs in it, which is fairly shocking since I used to write linked lists in C all the time.
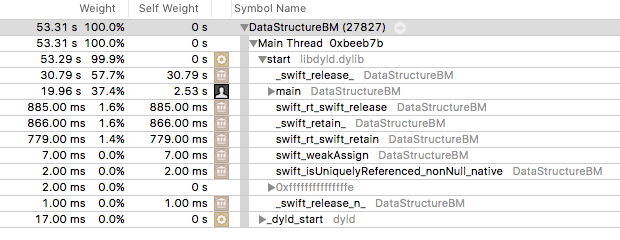
- Having profiled the code, I found that the program spends more than half its time in
_swift_retain. I think that is somewhat shocking too! The location in the call tree suggests that it’s happening mostly at the end i.e. it’s like an auto release pool is being drained, and, in fact, it might not be counting towards the timing.
Next Steps
I definitely need to investigate the release thing. There are ways to eliminate it, for example, I could put my deleted list items on a free list and perhaps reuse them, although that would not be a real life scenario. Also, I can try preallocating the array and/or list items but again, that would not be real life.
A criticism of the example is that a linked list is not the right structure to use for this problem, perhaps a binary tree would be better. Also, with the array, we can try a binary search algorithm, since it is ordered. Finally, I might try benchmarking using these structures as a queue or a stack. Both of these are applications where a linked list would hopefully do better.
